La chaire en Intelligence Artificielle « REMEMBER » proposée par un chercheur du LIRIS, a été sélectionnée par un comité international
La chaire IA « Remember : Learning Reasoning, Memory and Behavior », portée par Christian Wolf et impliquant Laetitia Matignon (LIRIS) et Olivier Simonin (CITI, Inria) et Jilles Dibangoye (CITI, Inria) étudiera les connexions entre apprentissage automatique, le contrôle optimal et la robotique. Elle est financé par l’Agence Nationale de la Recherche (ANR), par l’entreprise Naver Labs Europe et par l’INSA de Lyon.
Les dernières années ont été marquées par l’essor du Machine Learning, qui a permis des gains en performances significatifs dans plusieurs domaines d'application. Outre les progrès méthodologiques indéniables, ces gains sont souvent attribués à des grandes quantités de données d'entraînement et à la puissance de calcul, qui ont conduit à des avancées dans la reconnaissance de la parole, la vision par ordinateur et le traitement automatique de la langue. Dans ce projet ambitieux, nous proposons d'étendre ces avancées à la prise de décision séquentielle d'agents dans un contexte de planification et de contrôle dans des environnements 3D complexes.
Dans ce projet de chaire, nous proposerons des contributions méthodologiques (modèles et algorithmes) pour l’entrainement d’agents réels et virtuels leur permettant d’apprendre à résoudre des tâches complexes de manière autonome. Les agents intelligents requièrent des capacités de raisonnement de haut niveau, une conscience de leur environnement, et la capacité de prendre les bonnes décisions au bon moment.
Nous pensons que l’apprentissage des politiques de décisions dépendra de la capacité de l'algorithme à apprendre des représentations compactes de mémoire, structurées spatialement et sémantiquement, capables de capturer des régularités complexes de l’environnement et de la tâche en question. Une deuxième exigence clé est la capacité d'apprendre ces représentations avec un minimum d'interventions et d’annotations humaines, la conception manuelle de représentations complexes étant impossible.
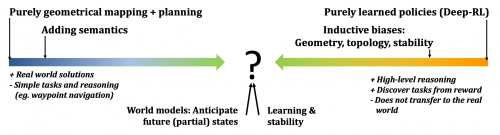
Ce projet de recherche vise à traiter ces problèmes selon quatre axes: (i) l’ajout de structures et de connaissances a priori aux algorithmes d’apprentissage par renforcement leur permettant de découvrir des représentations sémantiques et spatiales dotées de propriétés métriques et topologiques; (ii) l'apprentissage de modèles capables de généraliser à des environnements réels en combinant géométrie et apprentissage auto-supervisé; (iii) l'apprentissage de modèles de l’environnement anticipant des états futurs, et (iv) l'ajout aux algorithmes RL de biais inductif de stabilité venant de la théorie du contrôle.
Les avancées méthodologiques prévues dans ce projet seront évaluées sur des applications complexes, en partie dans des environnements simulés, en partie dans des environnements réels avec des robots physiques.