Lessons:
3. Constructivist epistemology
Home » 4. Self-programming » 44. Constructing reality
As showed in the algorithm in Table 33-3, the anticipate() function returns a list of anticipations. Each anticipation corresponds to an experiment associated with a proclivity value for performing this experiment. The proclivity is computed on the basis of the possible interactions that may actually be enacted as an effect of performing this experiment, as far as the system can tell from its experience.
For the anticipate() function to work similarly with composite interactions as it does with primitive interactions, composite interactions must also be associated with experiments. In fact, the system must learn that a composite interaction corresponds to an abstract experiment performed with reference to an abstract environment (the reactive part) that returns an abstract result.
See how this problem fits nicely with the constructivist learning challenge (introduced in the readings on Page 36): learning to interpret sensorimotor interactions as consisting of performing experiments on an external reality, and to interpret the results of these experiments as information about that reality.
The rest of this page presents our first step towards addressing this challenge. We will develop this question further in the next lesson.
Figure 44 illustrates the implementation of the learnCompositeInteraction() function so as to implement recursive learning of a hierarchy of composite interactions.
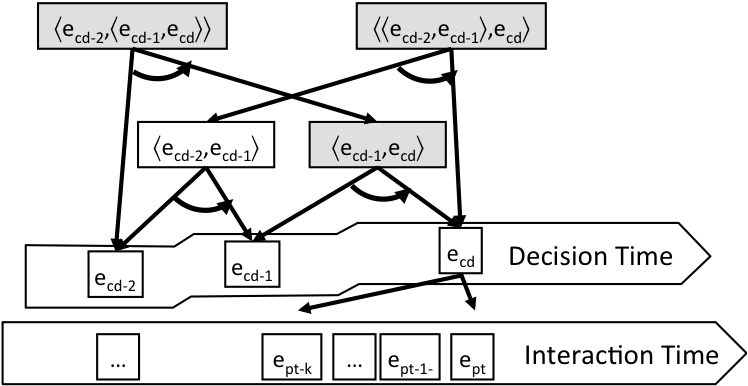
Figure 44: Recursive learning of composite interactions.
Figure 44 distinguishes between the Interaction Time (arrow at the bottom corresponding to the agent/environment coupling) and the Decision Time (staircase shaped arrow corresponding to the proactive/reactive coupling that rises over time). The learning occurs at the level of the Decision Time to learn higher-level composite interactions on top of enacted composite interactions. In gray rectangles indicate the composite interactions that are learned or reinforced at the end of decision cycle td. The system learns the composite interaction ⟨ecd-1,ecd⟩ made of the sequence of the previous enacted composite interaction ecd-1 and the last enacted composite interaction ecd. This is similar to Page 32 except that the learning can apply to composite interactions rather than primitive interactions only. Additionally, the system learns the composite interaction ⟨ecd-2,⟨ecd-1,ecd⟩⟩. This way, if ecd-2 is enacted again, ⟨ecd-2,⟨ecd-1,ecd⟩⟩ will be re-activated and will propose to enact its post-interaction ⟨ecd-1,ecd⟩. The system has thus learned to re-enact ⟨ecd-1,ecd⟩ as a sequence, hence the self-programming effect. The higher-level composite interaction ⟨⟨ecd-2,ecd-1⟩,ecd⟩ is also learned so that it can be re-activated in the context when ⟨ecd-2,ecd-1⟩ is enacted again, and propose its post-interaction ecd.
When a new composite interaction ic is added to the set Id of known interactions at time td, a new abstract experiment ea is added to the set Ed of known experiments at time td, and a new abstract result ra is added to the set Rd of known results at time td, such that ic = ⟨ea,ra⟩.
Abstract experiments are called abstract because the environment cannot process them directly. The environment (or robot's interface) is only programmed to interpret a predefined set of experiments that we now call concrete. To perform an abstract experiment ea, the agent must perform a series of concrete experiments and check their results. That is, the agent must try to enact the composite interaction ic from which the abstract experiment ea was constructed.
If the chooseExperiment() function chooses experiment ea, then the system tries to enact ic. If this tentative enaction fails and results in the enacted composite interaction ec ∈ Id+1, then the system creates the abstract result rf ∈ Rd+1, so that ec = ⟨ea,rf⟩ .
The next time the system considers choosing experiment ea, it will compute the proclivity for ea based on the anticipation of succeeding enacting ic and getting result ra, balanced with the anticipation of actually enacting ec and getting result rf.
As a result of this mechanism, composite interactions can have two forms: the sequential form ⟨pre-interaction,post-interaction⟩ and the abstract form ⟨experiment,result⟩. We differentiate between these two forms by noting abstract experiments and results in initial caps separated by the "|" symbol: ⟨EXPERIMENT|RESULT⟩. We will use this notation in the trace in Page 46.
This mechanism is a critical step to implementing self-programming agents. Nevertheless, it opens many questions that remain to be addressed. For example, how to organize experiments and results to construct a coherent model of reality?
See public discussions about this page or start a new discussion by clicking on the Google+ Share button. Please type the #IDEALMOOC044 hashtag in your post: