Lessons:
3. Constructivist epistemology
Home » 4. Self-programming » 43. Architecture
By building upon the regularity learning algorithm presented on Page 33, Table 43 presents our first algorithm for self-programming agents.
Table 43: Algorithm of a recursive self-programming agent.
001 createPrimitiveInteraction(e1, r1, -1) 002 createPrimitiveInteraction(e1, r2, 1) 003 createPrimitiveInteraction(e2, r1, -1) 004 createPrimitiveInteraction(e2, r2, 1) 005 while() 006 anticipations = anticipate() 007 experiment = selectExperiment(anticipations) 008 intendedInteraction = experiment.intendedInteraction() 009 enactedInteraction = enact(intendedInteraction) 010 learn() 011 if (enactedInteraction.valence ≥ 0) 012 mood = PLEASED 013 else 014 mood = PAINED 101 function enact(intendedInteraction) 102 if intendedInteraction.isPrimitive 103 experiment = intendedInteraction.experiment 104 result = environment.getResult(experiment) 105 return primitiveInteraction(experiment, result) 106 else 107 enactedPreInteraction = enact(intendedInteraction.preInteraction) 108 if (enactedPreInteraction ≠ intendedInteraction.preInteraction) 109 return enactedPreInteraction 110 else 111 enactedPostInteraction = enact(intendedInteraction.postInteraction) 112 return getOrLearn(enactedPreInteraction, enactedPostInteraction) 201 function environment.getResult(experiment) 202 if penultimateExperiment ≠ experiment and previousExperiment = experiment 203 return r2 204 else 205 return r1
Table 43, lines 001-014: The main loop of the algorithm is very similar to that on Page 33. 001-004: Initialization of the primitive interactions. 006: Get the list of anticipations. Now, the anticipate() function also returns anticipations for abstract experiments corresponding to enacting composite interactions. 007: Choose the next experiment from among primitive and abstract experiments in the list of anticipations. 008: Get the intended primitive or composite interaction from the selected primitive or abstract experiment.
Line 009: The enaction of the intended interaction is now delegated to the recursive function enact(intendedInteraction). The intended interaction constitutes the learned program that the agent intends to execute, and the enact() function implements the engine that executes it. Let us emphasize the fact that the agent now chooses an interaction to enact rather than an experiment to perform (as it was the case on Page 33). In return, the agent receives an enacted interaction rather than a result. This design choice follows from constructivist epistemology which suggests that sensorimotor patterns of interaction constitute the basic elements from which the agent constructs knowledge of the world.
Line 010: Learns composite interactions and abstract experiments from the experience gained from enacting the enacted interaction. The learn() function will be further explained on the next page. Lines 011 to 014: like before, specify that the agent is pleased if the enacted interaction's valence is positive, and pained otherwise. The valence of a composite interaction is equal to the sum of the valences of its primitive interactions, meaning that enacting a full sequence of interactions has the same motivational valence as enacting all its elements successively.
Lines 101-116: The function enact(intendedInteraction) is used recursively to control the enaction of the intended interaction all the way down to the primitive interactions. It returns the enacted interaction. 102-105: If the intended interaction is primitive then it is enacted in the environment. 103: Specifies that the experiment is the intended primitive interaction's experiment. 104: The environment returns the result of this experiment. 105: The function returns the enacted primitive interaction made from the experiment and its result. 106-112: Control the enaction of a composite intended interaction. Enacting a composite interaction consists of successively enacting its pre-interaction and its post-interaction. 107: Call itself to enact the pre-interaction. 108-109: If the enacted pre-interaction differs from the intended pre-interaction the enact() function is interrupted and returns the enacted pre-interaction. 110-111: if the enaction of the pre-interaction was a success, then the enact() function proceeds to the enaction of the post-interaction. 112 The function returns the enacted composite interaction made of the enacted pre-interaction and of the enacted post-interaction.
Lines 201-205 implement the environment. This environment is the simplest we could imagine that requires the agent to program itself if it wants to be PLEASED. The result r2 occurs when the current experiment equals the previous experiment but differs from the penultimate experiment, and r1 otherwise. Since r2 is the only result that produces interactions that have a positive valence, and since the agent can at best obtain r2 every second step, it must learn to alternate between two e1 and two e2 experiments: e1→r1 e1→r2 e2→r1 e2→r2 etc. The agent must not base its decision on the anticipation of what it can get in the next step, but on the anticipation of what it can get in the next two steps.
Figure 43 illustrates the architecture of this algorithm.
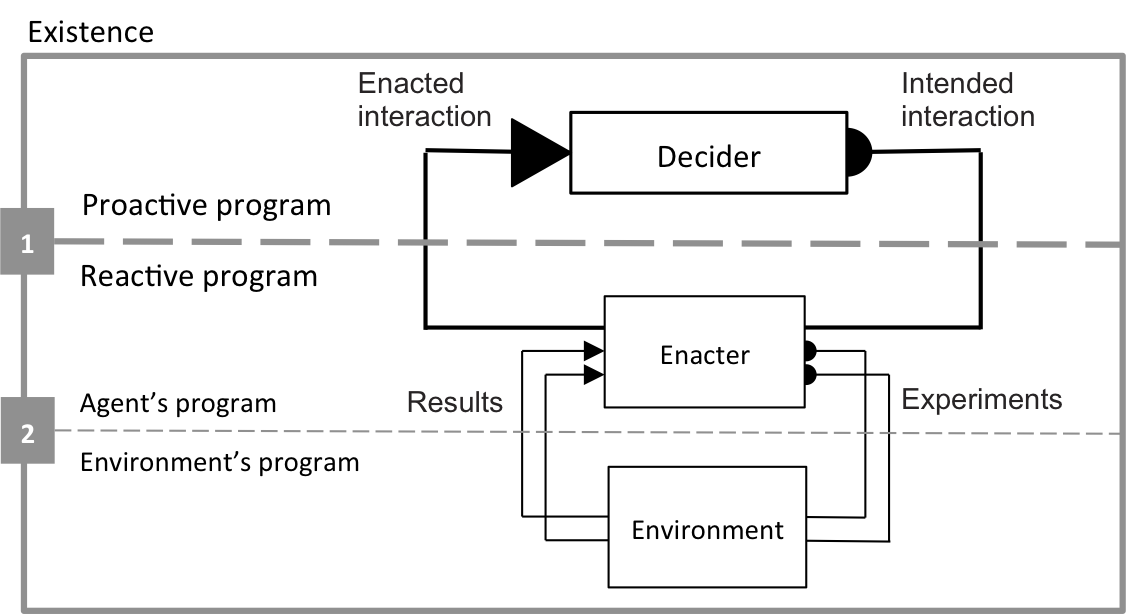
Figure 43: Self-programming agent architecture.
The whole program is called Existence. The lower dashed line (Line 2) separates the part of existence corresponding to the agent (above Line 2) from the part corresponding to the environment (below Line 2, implemented by the function environment.getResult(experiment)). The upper dashed line (Line 1) separates the proactive part of existence (above Line 1) from the reactive part of existence (below Line 1). The program that implements the proactive part is called the Decider; you can consider this as the "cognitive part" of the agent. It corresponds to the main loop in Table 43: lines 005 to 014. The reactive part of the existence includes both the Enacter (above Line 2) and the environment (below Line 2). The enacter (function enact()) controls the enaction of the intended interaction by sending a sequence of experiments to the environment. The enacter receives a result after each experiment. After the last experiment, the enacter returns the enacted composite interaction to the decider.
As the agent develops, it constructs abstract possibilities of interaction (composite interactions) that it can enact with reference to the reactive part. From the agent's cognitive point of view (the proactive part), the reactive part appears as an abstract environment (abstracted away from the real environment by the agent itself). Line 1 represents what we call the cognitive coupling between the agent and its environment.
In Lessons 5 and 6, we will discuss the question of increasing the complexity associated with these different levels of coupling.
See public discussions about this page or start a new discussion by clicking on the Google+ Share button. Please type the #IDEALMOOC043 hashtag in your post: