Lessons:
3. Constructivist epistemology
Home » 4. Self-programming » 42. Exploiting regularities
We already introduced the problem of learning regularities on Page 32. There was, however, no self-programming in this exemple because the system could not re-enact the learned regularities as full sequences of interactions. Figure 42 builds upon the regularity learning mechanism to present our design principles for self-programming.
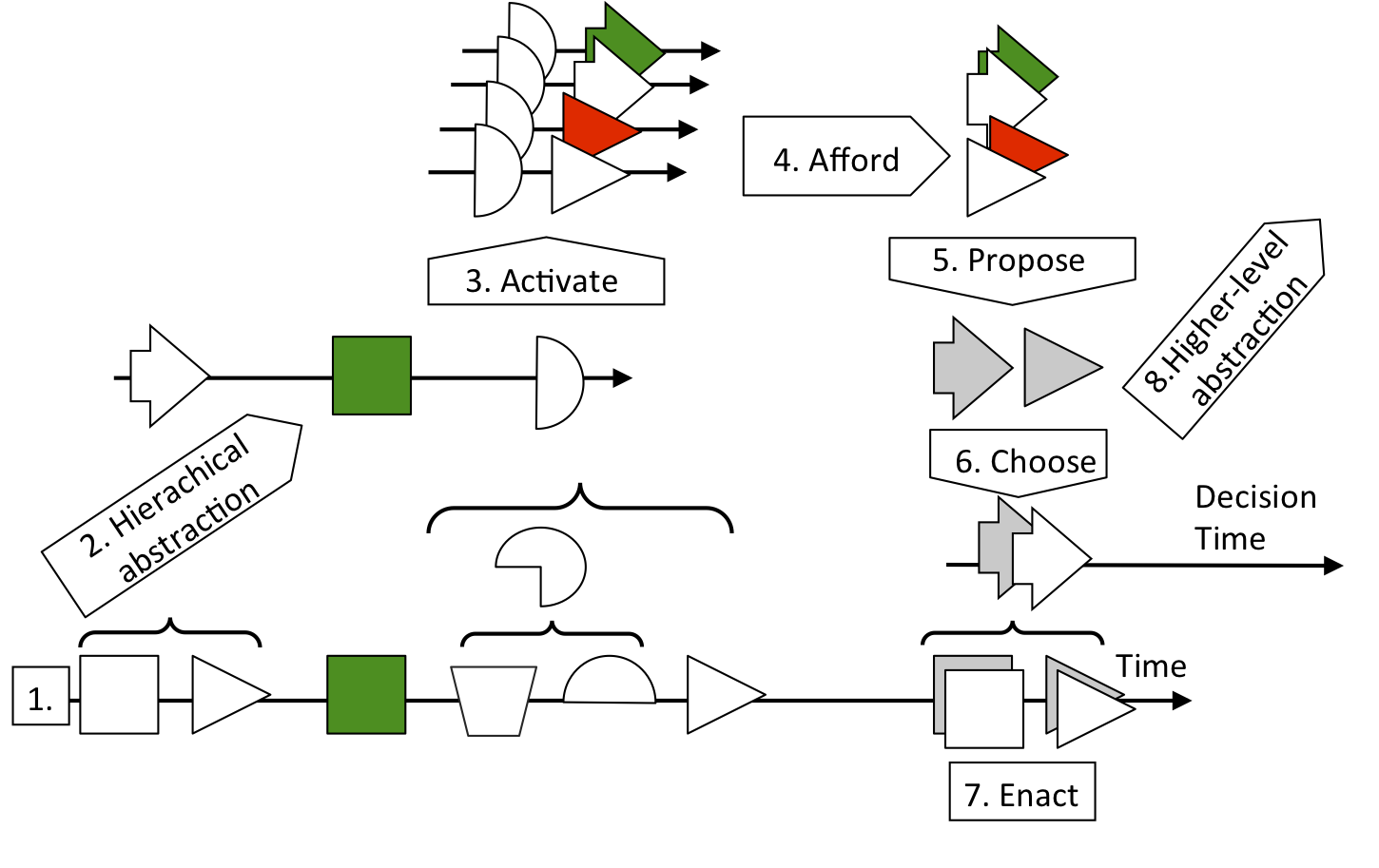
Figure 42: Hierarchical regularity learning for self-programming.
Figure 42: 1) The time line at the bottom represents the stream of interactions that occur over time as the system interacts. Symbols in this time line represent enacted interactions as in the bottom line of Figure 32. 2) The agent finds episodes of interest made of sequences of interactions. The symbols above Line 1 represent episodes delimited by curly brackets. These episodes are learned hierarchically in a bottom-up way; higher-level episodes are made of sequences of lower-level episodes. 3) At a certain level of abstraction (white vertical half-circle), the current sequence of episodes matches previously learned sequences and re-activates them. 4) Re-activated sequences propose subsequent episodes. These are, thus, the episodes that are afforded by the current context. 5) Afforded episodes are categorized as experiments (gray symbols). These experiments are proposed for selection. 6) The agent chooses an experiment from amongst the proposed experiments (gray arrow). 7) The agent tries to enact the sequence of primitive interactions that correspond to the chosen experiment. The success or failure of this tentative enaction depends on the environment. If the activated sequences do indeed represent a regularity of interaction, then it is probable that the tentative enaction will succeed (white arrow). However, it is not certain.
The self-programming effect occurs when the chosen experiment corresponds to a composite interaction. In this case, the decision engages the agent into executing several steps of interaction.
Self-programming results in a bottom-up automatization of behaviors so that the agent constructs increasingly abstract behaviors and delegates the control of their enaction to an automatic subsystem of its cognitive system. The agent can focus on the abstract behavior (Decision Time arrow in Figure 42) which helps it to deal with the complexity of its environment and recursively construct even higher levels of abstraction.
The agent represents its current context in terms of previously learned abstract episodes of interaction. This amounts to modeling the environment in terms of abstract affordances, as, for example, Gibson suggests in his theory of affordances.
This learning process is incremental and open-ended; it only stops when it runs out of memory for recording new sequences. Memory could be optimized, for example, by deleting (forgetting) sequences that have not been used for a while, but we did not implement this for the sake of simplicity. More fundamentally, regularities should be used to construct a coherent model of the world; we will examine this issue further in Lesson 6.
See public discussions about this page or start a new discussion by clicking on the Google+ Share button. Please type the #IDEALMOOC042 hashtag in your post: