A.B.S.T.R.A.C.T.
ANALYSIS OF BEHAVIOR AND SITUATION FOR MENTAL REPRESENTATION ASSESSMENT AND COGNITIVE ACTIVITY MODELLING
- Objectif: Analyse instrumentée dune activité humaine
- Cadre théorique
- En sciences humaines: «Exploratory Sequential Data Analysis»
- En informatique : «Knowledge Discovery»
- Principe méthodologique: Un processus dabstraction
- Interface utilisateur
- Exemple 1
- Exemple 2
- Publications
Objectif: Analyse instrumentée dune activité humaine
Le projet ABSTRACT est un projet de recherche en sciences cognitives qui couvre à la fois les champs de lergonomie cognitive et de linformatique.
Nous nous adressons aux personnes qui cherchent des moyens de mieux comprendre une activité humaine à partir dun enregistrement informatisé de cette activité.
Nos objectifs sont des objectifs dergonomie, dans le sens général d'une «science de lactivité humaine». Les buts peuvent être multiples: faciliter l'activité, prédire l'activité, prévenir certaines actions indésirables, etc. Pour cela nous développons une méthodologie et des outils facilitant la «découverte de connaissances à partir de traces dactivité».
Cadre théorique
En sciences humaines: Exploratory Sequential Data Analysis
Du point de vue des sciences humaines, nous nous reconnaissons dans le champ de recherche que Penelope Sanderson et Carolanne Fischer nomment «Exploratory Sequential Data Analysis (ESDA)» dans leur article de 1994: «Exploratory Sequential Data Analysis : Fondations».
Cet article définit les objectifs de lESDA ainsi: Analyzing sequential data with a quest for their meaning in relation to some research or design question. Il sagit dune démarche exploratoire qui vise à Looking at data to see what it seems to say plutôt que dune démarche de confirmation dhypothèse qui viserait leur validation ou invalidation statistique.
En informatique : « Knowledge Discovery »
Du point de vue de linformatique et de lingéniérie des connaissances, nous nous reconnaissons dans le domaine du « Knowledge Discovery » tel que Usama Fayyad le présente dans son article de 1996: «From Data Mining to Knowledge Discovery in Database».
Au-delà du problème de «pattern finding» et de lapprentissage automatique par des algorithmes de «data mining», le «Knowledge Discovery» interroge la question épistémologique de la signification des «patterns» découverts.
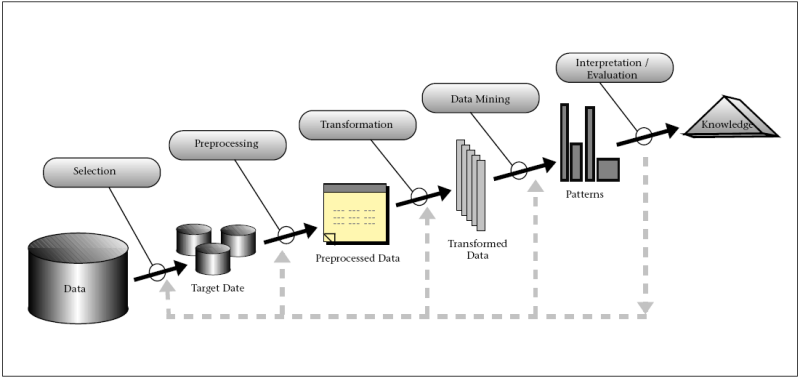
Figure 1: Steps that compose the KDD process - Fayyad 1996.
Nous insistons sur la nécessité de « garder lhomme dans la boucle » du cycle de «knowlege discovery» tel que Fayyad le présente figure 1. Nous proposons une approche par niveaux successifs dabstraction, continuellement confrontés à linterprétation de lergonome. La connaissance ne se trouve pas construite dans loutil informatique mais « dans la tête » de lergonome en interaction avec loutil. Au fur et à mesure de cette interaction, la connaissance est cependant capitalisée dans loutil sous forme dune amélioration progressive des règles dinférence et de visualisation des données.
Principe méthodologique: Un processus dabstraction
Les données brutes
Nous débutons par une observation de lactivité qui peut prendre des formes multiples: directement par lergonome, par des caméras vidéo ou microphones, par des capteurs qui enregistrent des données numériques, par des «logs» de programmes informatiques, etc.
Dans notre travail les données sont collectées avec un véhicule instrumenté lors d'expérimentation de conduite automobile. Les données sont obtenues par des caméras, des capteurs (vitesse, angle volant, enfoncement des pédales, télémètre, position GPS, oculomètre), et par interview du conducteur.
Dans tous les cas l'observation doit produire un ensemble de données datées, c'est-à-dire que chaque élément dinformation est rattaché à un instant de lactivité repéré par un « Time-Code ».
Ces données datées constituent nos données brutes. Leur choix et leur forme ne sont pas neutres, elles se basent sur notre connaissance initiale de lactivité étudiée et sur nos objectifs de recherche.
Le pré-processing
Cette étape de pré-processing inclut les traitements de bas niveau tels que la calibration des capteurs, le filtrage du « bruit », lélimination des variables non intéressantes.
La trace collectée
La trace collectée est le résultat dune «discrétisation» des données. Par exemple nous extrayons les points remarquables des courbes analogiques (Seuils, Mins et Max locaux, Points d'inflexion) (figure2); ou des événements de déclenchement de zones dintérêt dun oculomètre (figure 3); ou encore nous convertissons des «logs» bruts d'applications informatiques en des événements significatifs.
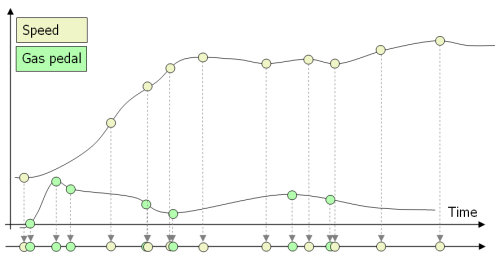
Figure 2: Discrétisation des données analogiques.

Figure 3: Zones d'intérêt oculomètre.
Cette discrétisation produit une suite dévénements auxquels sont rattachés des propriétés numériques ou textuelles. Nous appelons cette suite dévénements la « trace collectée ». Elle constitue le point de départ des différentes traces symboliques que nous produisons.
Cette trace collectée doit être validée par lergonome afin de sassurer que les événements qu'elle contient soient significatifs. Le réglage des différents paramètres qui permettent de la générer est une étape importante. Pour permettre cette validation, nous avons développé un outil qui permet de la visualiser sous Excel de manière synchrone avec la vidéo. Lorsque lergonome joue la vidéo, la trace est automatiquement scrollée dans Excel (figure 4). Chaque ligne représente un événement; la colonne 1 contient son Time-Code en secondes, la colonne 4 contient son type, les colonnes suivantes contiennent ses propriétés.
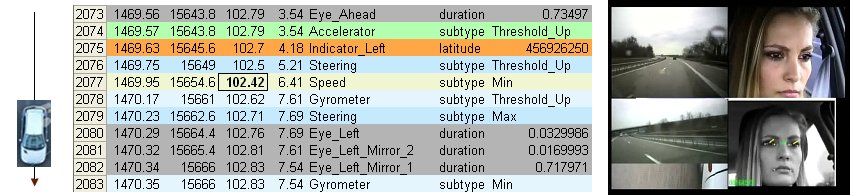
Figure 4: Contrôle de la Trace collectée sous Excel.
La vidéo nest pas entièrement transcodée symboliquement et reste exploitée par l'ergonome en parallèle avec les traces symboliques.
Les traces analysées
La trace collectée est ensuite convertie en graphe RDF de façon à pouvoir être enrichie par des symboles plus abstraits (figure 5). Les ronds représentent les événements de la trace collectée, les triangles et les carrés représentent les événements plus abstraits, et les flèches représentent les relations d'inférence.
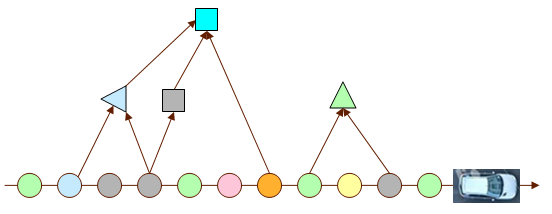
Figure 5: Inférence de descripteurs abstraits.
Les règles d'inférence sont écrites sous forme de requêtes SPARQL. L'outil ABSTRACT permet de générer ces requêtes de manière semi-graphique, c'est-à-dire que l'ergonome produit interactivement des squelettes de requêtes, qu'il doit compléter manuellement.
En parallèle à la création des requêtes, l'ergonome définit les symboles qu'il crée dans une ontologie. Nous mettons à sa disposition l'éditeur d'ontologie Protégé pour lui permettre de définir les propriétés sémantiques et visuelles de ses symboles. Cette ontologie est exploitée par le moteur d'inférence SPARQL et par les modules de visualisation graphique des traces.
Interface utilisateur
La Figure 6 montre une copie d'écran de l'interface autilisateur.
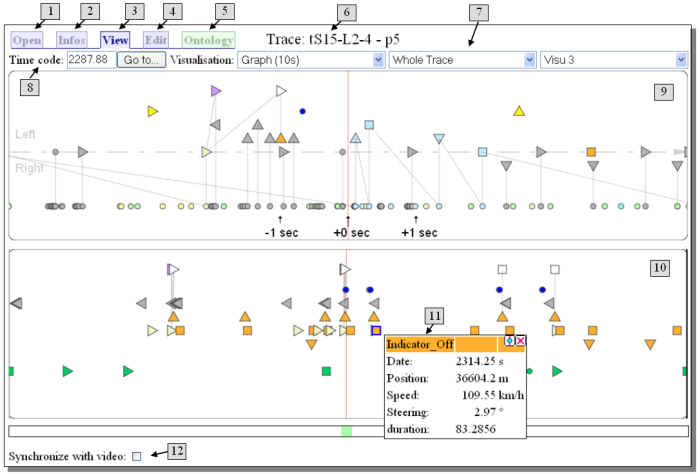
Figure 6: Interface utilisateur d'Abstract.
Cette interface offre les fonctionnalités suivantes: (1,6) choisir une trace, (2) voir les informations générales des cette trace, (3) visualiser la trace sous différent formats, (4) transformer la traces par l'application de règles de transformation, (5) définir les symboles dans une ontologie, (7) choisir différents modules de visualisation, (8) atteindre un time code particulier.
Le module de visualisation (10) montre la trace complète avec les symboles de haut niveau, le module (9) montre un zoom sur un interval de 10 secondes. Un click sur les symboles permet d'afficher une fênetre d'information (11). L'utilisateur peut fare glicer la trace horizontalement et la synchroniser avec une vidéo (12).
Exemple 1
La figure 7 est une représentation graphique d'une séquence typique de dépassement sur autoroute, telle qu'elle est produite par ABSTRACT; à laquelle les libellés ont été rajoutés.

Figure 7: Schéma de dépassement sur autoroute.
Dans cette visualisation, l'abscisse des événements représente leur time-code, et leur ordonnée différentie leurs niveaux d'abstraction. La forme des symboles et leur ordonnée est définie par l'ergonome dans l'ontologie. Dans cette figure, les symboles de bas niveau sont les cercles en bas de la figure. Les symboles de niveau d'abstractuion intermédiaire sont placés autour de l'axe central. Ce qui concerne la gauche du véhicule est placé au dessus de l'axe central, et ce qui concerne la droite en dessous. Les triangles orientés vers la droite represente quelquechose "vers l'avant" (par exemple: "Look ahead"). Les triangles ortientés ver la gauche représentent quelquechose "vers l'arrière" (par exemple: "Left mirror glance"). Les lignes représentent les relations d'inférence allant de symboles de bas niveau vers des symboles de plus haut niveau. La partie la plus haute de l'affichage représente les symboles de plus haut niveau d'abstraction. Par exemple, la "Decision" de changer de voie est inféré à partir d'une cooccurence d'une accélération et d'un regarde vers le retroviseur gauche.
Exemple 2
La figure 8 montre l'activité terroriste en République Irlandaise entre 1970 et 2007. Les données proviennent de la Global Terrorism Database (GTD).

Figure 8: Activité terroriste en Rébublique Irlandaise.
La visualisation du haut représente un zoom sur un interval de 100 jours. La visualisation du bas représente les 37 années.
Dans ces visualisations, l'icone principale est associéee au champ "WEAPON_TYPE". Les trois principaux types d'armes sont représentés: "Firearms" (pistolet), "Explosive" (étoile) et "Incendiary" (flamme). Une deuxième icone représentant les contours d'un corps est ajoutée quand le champ "ATTACK" vaut "assassination".
L'ordonnée est associée au champ "PERPETRATOR", c'est à dire que les principaux groupes terroristes sont représentés chacun sur une ligne distincte. Les groupes loyalistes (protestants) sont représentés au dessus de l'axe central, les groupes républicains (catholiques) sont représentés en dessous de l'axe central.
Dans cet exemple, l'ontologie est hébergée en ligne sous forme d'un Semantic-Media-Wiki. La fenêtre info-bulle d'un évenement fournit les liens vers les différentes classes définies dans l'ontologie. Le champ "GTD_ID" fournit un lien vers la description de l'événement dans la Global Terrorism Database.
L'utilisateur d'ABSTRACT définit la visualisation dans une feuille de style XSL qui exploite des paramètres définis dans l'ontologie.
Démonstration
Une version simplifiée d'ABSTRACT est disponible gratuitement en ligne. Cette version s'appelle ABSTRACT-LITE. Une documentation est également fournie.
Téléchargement
ABSTRACT est disponible au téléchargement depuis le serveur SVN du Liris à cette addresse. Il est en lecture seule. Si vous voulez contribuer au développement, merci de contacter les auteurs.
Publications
Supporting Activity Modeling from Activity Traces. Olivier L. Georgeon, Alain Mille, Thierry Bellet, Benoit Mathern, Frank E. Ritter (2012). Expert Systems, 29 (3), 261-275. doi: 10.1111/j.1468-0394.2011.00584.x.
Early-Stage Vision of Composite Scenes for Spatial Learning and Navigation. In the proceedings of the First Joint IEEE Conference on Development and Learning and on Epigenetic Robotics (ICDL-EPIROB 2011). Olivier L. Georgeon, James B. Marshall, Pierre-Yves R. Ronot. Frankfurt (24-27 August 2011).
A Comparative study of Exploratory Sequential Data Analysis tools. 2010. Sowmyalatha Srinivasmurthy. Technical report. The Pennsylvania State University.
Other publications on CiteUlike.









