We compare our method with the single view method of [Bonneel et al. 2015] applied to a "linearization" of our multi-view sequences. This "linearization" is computed by sweeping all views for each frame of the video in the following way:
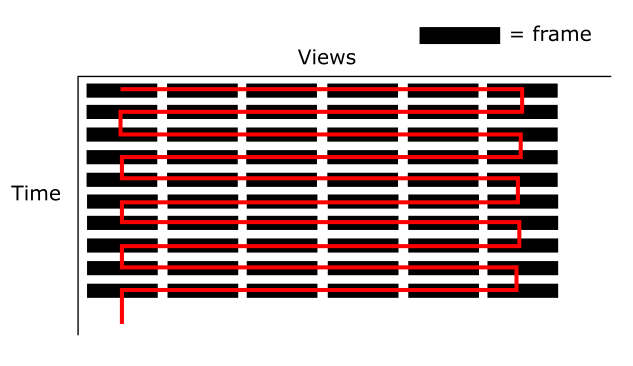 For fair comparison, the per-view output computation of Bonneel et al. 2015 and the output computation of our anchor-based approach have been reordered in a similar way
For fair comparison, the per-view output computation of Bonneel et al. 2015 and the output computation of our anchor-based approach have been reordered in a similar way