Heuristiques et recherche locale itérative
Table of Contents
- 1. Tous les noeuds atteignables à partir d'un noeud source
- 2. Recherche en largeur (breadth-first search)
- 3. Recherche en profondeur (depth-first search)
- 4. Plus court chemin sur un graphe aux arêtes étiquetées positivement (Dijkstra)
- 5. Plus court chemin en présence d'information contextuelle
- 6. Exemple sur le jeu de taquin de taille 8
- 6.1. Contexte
- 6.2. Heuristiques
- 6.3. Implémentation
- 6.3.1. Types (
<<taquin-types>>) - 6.3.2. Taille du côté d'une grille (
<<taquin-side>>) - 6.3.3. Heuristiques (
<<taquin-heuristics>>) - 6.3.4. Configuration cible (
<<taquin-final_state>>) - 6.3.5. \(A^*\) (
<<taquin-astar>>) - 6.3.6. Distance pour les noeuds gris et noirs (
<<taquin-astar-dist>>) - 6.3.7. Mise à jour de la file de priorité (
<<taquin-astar-update>>) - 6.3.8. Rerconstruction du chemin solution (
<<taquin-astar-stop>>) - 6.3.9. Calcul des voisins (
<<taquin-astar-neighbors>>) - 6.3.10. Initialisation des structures de données (
<<taquin-astar-init>>) - 6.3.11. Afficher une grille (
<<taquin-print>>) - 6.3.12. Librairies utilisées (
<<taquin-include>>) - 6.3.13. Programme principal (
taquin.cpp)
- 6.3.1. Types (
- 6.4. Résultats
- 7. Exemple sur le jeu de taquin de taille 15
- 8. Approfondissement itéré (iterative deepening)
- 9. Approfondissement itéré pour l'algorithme A* (IDA*)
- 10. Recherche locale itérative et recuit simulé
1 Tous les noeuds atteignables à partir d'un noeud source
1.1 Dérivation du programme à partir de sa spécification
1.1.1 Première esquisse
Étant donné un graphe orienté G et un nœud \(v\) de ce graphe, nous cherchons à calculer l'ensemble des nœuds atteignables à partir de \(v\).
Nous notons \(s\) la fonction "successeur" qui retourne les voisins directs d'un ensemble de nœuds.
Nous définissons la fonction \(a\) ("atteignable") :
\begin{equation*} a(x) = x \cup a(s(x)) \end{equation*}Les solutions de cette équation sont de la forme \(a(u) = u\) (i.e., quand \(s(u) \subseteq u\) ).
L'ensemble des nœuds atteignables à partir de l'ensemble de nœuds \(x\) est le plus petit ensemble qui inclut \(x\) et qui est solution de l'équation ci-dessus. Sans cette précision, l'égalité ci-dessus ne pourrait pas servir de définition pour \(a\). Par exemple, quelque soit \(x\), l'ensemble de tous les nœuds du graphe satisferait cette égalité.
Exercice : Montrer qu'un plus petit ensemble solution existe. C'est-à-dire, montrer qu'étant données \(u\) et \(v\) deux solutions (i.e., \(a(u)=u\) et \(a(v)=v\) ), \(a(u) \cap a(v)\) est également solution. Il s'en suit qu'étant donné \(x\), il existe un plus petit ensemble solution incluant \(x\) (viz. l'intersection de tous les ensembles qui sont solution et qui incluent \(x\) ).
Il s'agit de calculer un programme dont la post-condition est l'équation d'inconnue \(x\) suivante :
\begin{equation*} R: \;\; a(\{v\}) = x \end{equation*}Pour fixer les idées, nous pouvons avoir à l'esprit un exemple de graphe orienté (mais attention à ne pas être trop influencé par une configuration particulière…).
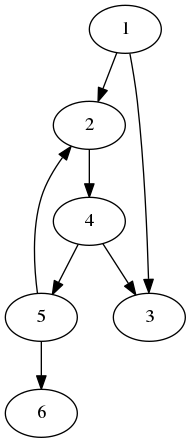
Figure 1: Graphe pour illustrer l'algorithme Atteignable
Nous avons par exemple :
\begin{equation*} a(\{4\}) = \{2,3,4,5,6\} \end{equation*}Nous cherchons une manière d'affaiblir la postcondition dans l'idée de découvrir un invariant. Nous remarquons :
\begin{equation*} a(x) = a(x \cup s(x)) \end{equation*}Exercice : Prouvez le.
Nous avons donc l'idée d'invariant :
\begin{equation*} P0 : \quad a(\{v\}) = a(x) \end{equation*}Et nous pouvons progresser vers la solution grâce à l'affectation :
\begin{equation*} x \gets x \cup s(x) \end{equation*}Mais, sous quelle condition devons-nous sortir de la boucle ? Nous remarquons :
\begin{equation*} s(x) \subseteq x \quad \Rightarrow \quad a(x) = x \end{equation*}Exercice : Prouvez le.
Nous avons donc montré que :
\begin{equation*} P0 \; \wedge \; (s(x) \subseteq x) \; \Rightarrow \; R \end{equation*}D'où une première version du programme :

Figure 2: Première version de l'algorithme Atteignable
1.1.2 Optimisation
Le programme que nous avons dérivé peut calculer plusieurs fois les successeurs d'un même nœud. Nous modifions l'invariant pour distinguer les nœuds dont les successeurs nous sont déjà connus (notés \(x\) et que nous appellerons aussi les nœuds noirs) de ceux déjà rencontrés mais dont les successeurs nous sont encore inconnus (notés \(y\) et que nous appellerons aussi les nœuds gris). Nous appellerons les nœuds encore non considérés : les nœuds blancs.
\begin{equation*} P1 : \quad a(\{v\}) = a(x \cup y) \;\; \wedge \;\; x \cap y = \emptyset \;\; \wedge \;\; s(x) \subseteq (x \cup y) \end{equation*}Ce qui nous dirige vers le nouveau programme optimisé :

Figure 3: Version optimisée de l'algorithme Atteignable
Le programme termine-t-il ? Le nombre de nœuds qui ne sont pas dans \(x\) est au moins égal à \(0\). A chaque itération, ce nombre décroît du nombre de nœuds de \(y\) ( car \(x \cap y = \emptyset\) ). Or le nombre de nœuds de \(y\) est strictement positif à cause de la clause garde de la boucle ( \(y \neq \emptyset\) ). Ainsi, nous avons isolé une fonction monotone stricte et bornée ("bound function") qui prouve la terminaison du programme.
Nous savons que ce programme est correct car nous l'avons dérivé à partir de sa spécification.
1.2 Implémentation C++
Nous proposons maintenant une implémentation du programme qui, étant donné un graphe orienté \(G\) et un nœud \(v\) de ce graphe, calcule l'ensemble des nœuds atteignables à partir de \(v\).
Nous utiliserons le langage C++11.
# code block: build_gdb.sh g++ -std=c++11 -g "$1.cpp" -o "$1"
# code block: build.sh g++ -std=c++11 -O3 "$1.cpp" -o "$1"
Nous utiliserons la librairie STL. Le programme sera introduit au moyen du
paradigme literate programming.
// code block reachable-include #include <iostream> #include <vector> #include <set> using namespace std;
Chaque nœud porte une valeur entière et une liste de voisins directs.
// code block reachable-struct-node struct node { int val; vector<node*> nei; };
Nous utilisons le même graphe exemple que celui dessiné plus haut.
// code block reachable-example struct node n1; n1.val = 1; struct node n2; n2.val = 2; struct node n3; n3.val = 3; struct node n4; n4.val = 4; struct node n5; n5.val = 5; struct node n6; n6.val = 6; n1.nei.insert(n1.nei.begin(), &n2); n1.nei.insert(n1.nei.begin(), &n3); n2.nei.insert(n2.nei.begin(), &n4); n4.nei.insert(n4.nei.begin(), &n3); n4.nei.insert(n4.nei.begin(), &n5); n5.nei.insert(n5.nei.begin(), &n2); n5.nei.insert(n5.nei.begin(), &n6);
Le code principal affichera simplement la liste des noeuds atteignables à partir d'un noeud source.
// code block: reachable.cpp <<reachable-include>> <<reachable-struct-node>> <<reachable-algo>> int main() { <<reachable-example>> for( node* n : a(&n4) ) { cout << n->val << " ; "; } cout << endl; return 0; }
Nous calculons la fermeture de la relation de voisinage avec l'algorithme dérivé plus haut.
// code block reachable-algo set<node*> a( node* src ) { set<node*> x; set<node*> y; y.insert(src); // the source is initially grey while( !y.empty() ) { set<node*>::iterator u = y.begin(); for( node* n : (*u)->nei ) // n is in the successors of y { if( (x.end() == x.find(n)) && (y.end() == y.find(n)) ) // n is not in (x U y) { y.insert(n); // we still didn't see the succ of n // thus, it is a grey node } } x.insert(*u); // the node u of y is now white y.erase(u); } return x; }
Nous avons par exemple :
\begin{equation*} a(\&n4) = 6 ; 5 ; 4 ; 3 ; 2 ; \end{equation*}2 Recherche en largeur (breadth-first search)
2.1 Structure FIFO
En utilisant pour \(y\) (la structure qui contient les nœuds rencontrés mais dont les successeurs n'ont pas encore été calculés) une structure de file FIFO (First In First Out) au lieu d'un ensemble, nous obtenons le programme de recherche en largeur dans un graphe.
Nous utilison la structure de file (queue) de la STL.
// code block breadth-include #include <iostream> #include <vector> #include <set> #include <queue> #include <map> #include <functional> #include <limits> using namespace std;
Nous suivons le schéma de l'algorithme générique atteignable dérivé plus haut.
// code block breath-algo typedef function<void(node*)> Visitor; void breadth( node* src, Visitor f ) { set<node*> x; // in the end x has only white nodes // during the process, it also stores // the grey nodes queue<node*> y; // y is the queue (FIFO) of grey nodes y.push(src); x.insert(src); while( !y.empty() ) // there are still grey nodes { node* u = y.front(); // u is the 'oldest' element of y f(u); // visit u for( node* n : u->nei ) { if( x.end() == x.find(n)){ // n is a black successor of u y.push(n); // n becomes grey x.insert(n); // n will be white once removed from y } } y.pop(); // u is now white } }
Ci-dessous un résultat possible pour un parcours en largeur sur l'exemple précédent en partant du nœud 1 comme source. Nous utilisons un visiteur trivial :
// code block breadth-visit Visitor visit = [](node* v){ cout << v->val << " ; "; };
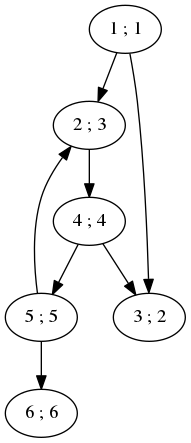
Figure 4: Graphe pour illustrer l'algorithme de parcours en largeur
2.2 Calcul des plus courts chemins
L'algorithme de recherche en largeur permet de trouver les plus courts chemins d'un nœud source aux autres nœuds du graphe dans le cas d'un graphe orienté pour lequel les arêtes ont toutes le même coût (ou poids) :
// code block breadth-dist void findDistances( node* src, map<node*,size_t>* distances ) { // local function used to return infinity when // for a node we didn't already find a distance function<size_t(node*)> distance = [distances]( node* v ) { map<node*,size_t>::iterator distIt = distances->find(v); if( distances->end() == distIt ) { return numeric_limits<size_t>::max(); } return distIt->second; }; Visitor visit = [distances, distance]( node* v ) { // distance to the source is zero if( distances->empty() ) (*distances)[v] = 0; // update the shortest known distance to the // successors of the currently visited node size_t vDist = distance(v); for (node* n : v->nei) { size_t nDist = distance(n); (*distances)[n] = min( nDist, 1 + vDist ); } }; breadth(src, visit); }
Le programme principal calcule les plus courtes distances au noeud source 1 sur notre exemple filé.
// code block: breadth.cpp <<breadth-include>> <<reachable-struct-node>> <<breadth-algo>> <<breadth-dist>> int main() { <<reachable-example>> <<breadth-visit>> breadth(&n1, visit); cout << endl; map<node*,size_t> distances; findDistances(&n1, &distances); for( map<node*,size_t>::iterator it = distances.begin() ; it != distances.end() ; it++ ) { cout << it->first->val << " : " << it->second << " ; "; } cout << endl; return 0; }
Nous trouvons bien :
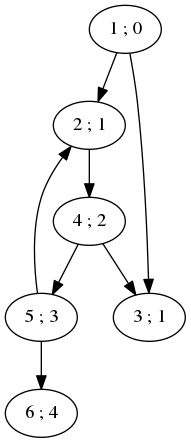
Figure 5: Graphe pour illustrer l'utilisation du parcours en largeur pour la découverte des plus courts chemins
3 Recherche en profondeur (depth-first search)
3.1 Structure LIFO (Last In First Out)
En utilisant pour \(y\) (la structure qui contient les nœuds rencontrés mais dont les successeurs ne sont pas encore calculés, les nœuds gris) une structure de pile LIFO (Last In First Out) au lieu d'un ensemble, nous obtenons le programme de recherche en profondeur dans un graphe.
Nous utilisons la structure de données stack de la STL.
// code block depth-include #include <iostream> #include <vector> #include <set> #include <queue> #include <map> #include <stack> #include <functional> #include <limits> using namespace std;
Le programme principal affichera simplement les noeuds dans l'ordre de leur visite en partant du noeud 1.
// code block: depth.cpp <<depth-include>> <<reachable-struct-node>> <<depth-algo>> int main() { <<reachable-example>> <<breadth-visit>> depth(&n1, visit); cout << endl; return 0; }
// code block: depth-algo typedef function<void(node*)> Visitor; void depth( node* src, Visitor f ) { set<node*> x; stack< pair< node* , vector<node*>::iterator > > y; y.push( { src, src->nei.begin() } ); // initially the source is grey x.insert(src); // x contains both the grey nodes // and the black nodes. In the end, // there are only black nodes. while( !y.empty() ) // while there are grey nodes... { node* u = y.top().first; // u is the grey node we will make black // by exploring his sons if( y.top().second != u->nei.end() ) // if u has still unexplored sons { node* next = *(y.top().second); // next is a son of u ++(y.top().second); if( x.end() == x.find(next) ) // if this son of u is white { y.push( { next, next->nei.begin() } ); // it becomes grey x.insert(next); } } else // u has no more unexplored sons. { f(u); // we can visit u y.pop(); // u is now black and can be removed from y } } }
Ci-dessous un résultat possible d'un parcours en profondeur sur l'exemple précédent en partant du nœud 1 comme source.
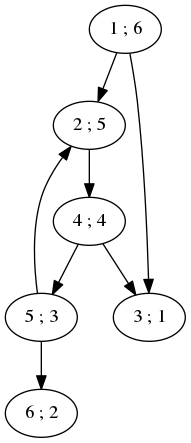
Figure 6: Graphe pour illustrer l'algorithme de parcours en profondeur
3.2 Version récursive
La recherche en profondeur s'écrit plus naturellement sous une forme récursive :
// code block depthrec-algo typedef function<void(node*)> Visitor; void depthrec( node* src, Visitor f, set<node*>* x ) { (*x).insert(src); for( node* n : src->nei ) { if( (*x).end() == (*x).find(n) ) { depthrec( n, f, x ); } } f(src); } void depth( node* src, Visitor f ) { set<node*> x; depthrec(src, f, &x); }
// code block depthrec.cpp <<depth-include>> <<reachable-struct-node>> <<depthrec-algo>> int main() { <<reachable-example>> <<breadth-visit>> depth(&n1, visit); cout << endl; return 0; }
4 Plus court chemin sur un graphe aux arêtes étiquetées positivement (Dijkstra)
4.1 Principe de l'algorithme
Nous considérons un graphe dont chaque arête est étiquetée avec un nombre positif ou nul. Il s'agit de calculer pour chaque nœud du graphe sa plus courte distance à un nœud \(v\) fixé. La plus courte distance entre deux nœuds est la longueur du plus court chemin entre ces deux nœuds.
L'ensemble des nœuds noirs est l'ensemble des nœuds pour lesquels la plus courte distance à \(v\) a été établie. Un plus court chemin ne visite que des nœuds noirs.
L'ensemble des nœuds gris est l'ensemble des nœuds pour lesquels la longueur d'un chemin y menant depuis \(v\) a été trouvée, mais cette longueur n'est pas nécessairement minimale. Par contre, c'est la longueur minimale sur l'ensemble des chemins qui n'ont que des nœuds noirs entre \(v\) et ce nœud gris.
Au sujet des nœuds blancs, nous ne savons rien… sinon que tout chemin depuis \(v\) jusqu'à un nœud blanc doit d'abord passer par un nœud gris.
On note \(d[u]\) la distance associée à un nœud noir ou gris.
Comment choisir le prochain nœud gris que nous ferons passer à noir ?
Nous montrons que nous pouvons choisir un nœud gris \(u\) dont la distance à \(v\), notée \(d[u]\), (et qui est la longueur d'un chemin ne passant que par des nœuds noirs) est minimale parmi l'ensemble des nœuds gris.
Considérons un chemin quelconque de \(v\) à \(u\) et notons sa longueur \(l\). Ce chemin peut contenir d'autres nœuds gris et même des nœuds blancs.
Puisque \(v\) est noir et \(u\) est gris, à un moment donné ce chemin quitte la région noire.
Soit \(g\) le premier nœud non-noir (c-à-d gris) de ce chemin.
\(g\) peut être égal à \(u\) ou ne pas être égal à \(u\).
Puisque \(u\) a été choisi pour minimiser \(d[u]\), nous avons : \(d[u] \leq d[g]\).
Puisque la distance de \(g\) à \(u\) est positive ou nulle, nous avons : \(d[g] \leq l\).
D'où : \(d[u] \leq l\). Donc ce chemin est au moins aussi long que celui dont la découverte avait mené à la mémorisation de la valeur actuelle \(d[u]\).
Donc la longueur du plus court chemin de \(v\) à \(u\) est \(d[u]\), et le nœud \(u\) peut être coloré en noir.
Tous les successeurs blancs de \(u\) sont colorés en gris, et une distance est mémorisée pour chacun d'entre eux, faite de la plus courte distance de \(v\) à \(u\) (\(d[u]\) ) à laquelle on ajoute la distance de \(u\) à ce successeur.
Tous les successeurs gris de \(u\) restent gris, mais la distance qui leur est associée peut être réduite (si le chemin qui passe par u est plus court).
Pour les successeurs noirs de \(u\), il n'y a rien à faire.
D'où l'algorithme suivant :

Figure 7: Algorithme de Dijkstra pour la recherche d'un plus court chemin
4.2 Implémentation
La liste d'adjacence d'un noeud contient maintenant les poids des arêtes qui permettent d'atteindre les voisins de ce noeud :
// code block dijkstra-struct-node struct node { int val; vector< pair< int, node* > > nei; };
Nous utilisons à nouveau la bibliothèque standard du C++.
#include <iostream> #include <vector> #include <set> #include <queue> #include <map> #include <list> #include <functional> #include <utility> #include <limits> using namespace std;
L'implémentation de l'algorithme suit d'assez près le pseudo-code de notre
dérivation. La différence principale réside dans l'utilisation d'une file de
priorité, et dans le maintient d'une structure map< node*, node* > parent qui
permet de reconstruire le chemin une fois la destination atteinte.
// code block dijkstra-algo void dijkstra( node* src, node* target, list<node*>* r ) { map< node*, node* > parent; parent[src] = src; map< node*, int> d; d[src] = 0; set<node*> x; priority_queue< pair< int, node* > , vector< pair< int, node* > >, greater< pair< int, node* > > > y; y.push({0, src}); x.insert(src); function<int(node*)> dist = [d]( node* v ) { map< node*, int >::const_iterator it = d.find(v); if( d.end() == it ) { return numeric_limits<int>::max(); } return it->second; }; while( !y.empty() ) { node* u = y.top().second; // once the target found, we rebuild the path to it if( target == u ) { r->clear(); while( u != src ) { r->push_front(u); u = parent[u]; } r->push_front(src); return; } x.insert(u); // u, the 'smallest' grey node, becomes black y.pop(); for( pair< int, node* > n : u->nei ) { if( x.end() != x.find(n.second) ) // if n is black, do nothing... { continue; } // We don't take into account as a special case the situation of // n already an element of y. // Indeed, the basic STL priority queue doesn't have // an increaseKey operation. // Therefore, we tolerate duplicates... // But really, we may prefer using a "better" structure... if( dist(n.second) > d[u] + n.first ) { d[n.second] = d[u] + n.first; parent[n.second] = u; y.push( { d[n.second], n.second } ); } } } }
4.3 Exemple
Nous mettons à jour notre petit exemple de graphe en ajoutant des poids aux arêtes :
// code block dijkstra-example struct node n1; n1.val = 1; struct node n2; n2.val = 2; struct node n3; n3.val = 3; struct node n4; n4.val = 4; struct node n5; n5.val = 5; struct node n6; n6.val = 6; n1.nei.insert(n1.nei.begin(), { 1, &n2 }); n1.nei.insert(n1.nei.begin(), { 4, &n3 }); n2.nei.insert(n2.nei.begin(), { 1, &n4 }); n2.nei.insert(n2.nei.begin(), { 2, &n5 }); n4.nei.insert(n4.nei.begin(), { 1, &n3 }); n4.nei.insert(n4.nei.begin(), { 2, &n5 }); n5.nei.insert(n5.nei.begin(), { 1, &n6 }); n6.nei.insert(n6.nei.begin(), { 1, &n2 });
Nous testons, sur cet exemple, l'algorithme de Dijkstra pour la recherche d'un plus court chemin.
// code block dijkstra.cpp <<dijkstra-include>> <<dijkstra-struct-node>> <<dijkstra-algo>> int main() { <<dijkstra-example>> list<node*> r; dijkstra(&n1, &n3, &r); for( list<node*>::iterator it = r.begin() ; it != r.end() ; it++ ) { cout << (*it)->val << " ; "; } cout << endl; return 0; }
Le résultat de la recherche du plus court chemin de 1 vers 3 donne bien :
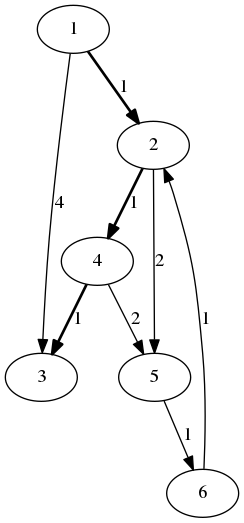
Figure 8: Graphe pour illustrer l'algorithme de Dijkstra pour la recherche d'un plus court chemin
5 Plus court chemin en présence d'information contextuelle
Comment améliorer la recherche d'un plus court chemin entre un nœud source \(s\) et un nœud cible \(t\) quand nous possédons pour tout nœud \(u\) du graphe une estimation \(h(u)\) de la distance séparant \(u\) de la cible ?
5.1 La notion de fonction heuristique
La fonction \(h\) est appelée fonction heuristique.
Déf. Une heuristique \(h\) est admissible si pour tout nœud \(u\), \(h(u)\) est une borne inférieure de la plus courte distance séparant \(u\) de la cible \(t\), i.e. \(h(u) \leq \delta(u,t)\) (avec \(\delta(u,t)\) désignant la longueur d'un chemin optimal entre \(u\) et \(t\) ).
Déf. Une heuristique \(h\) est consistante si pour toute arête \(e = (u,v)\) nous avons \(h(u) \leq h(v) + w(u,v)\) (avec \(w(u,v)\) le poids de l'arête \((u,v)\)).
Déf. Soient \((u_0,\dots,u_k)\) un chemin et \(g(u_i)\) le coût du chemin \((u_0,\dots,u_i)\). Nous posons \(f(u_i) = g(u_i) + h(u_i)\). Une heuristique \(h\) est monotone si pour tout \(j>i, \; 0 \leq i, \; j \leq k\) nous avons \(f(u_j) \geq f(u_i)\). C'est-à-dire que l'estimation du poids total d'un chemin ne décroît pas lors du passage d'un nœud à ses successeurs.
Nous remarquons que consistance et monotonicité sont deux propriétés équivalentes. En effet, pour deux nœuds adjacents \(u_{i-1}\) et \(u_i\) sur un chemin \((u_0,\dots,u_k)\), nous avons :
\begin{equation*} \begin{aligned} & f(u_i) \\ = \quad &\{\text{Déf. de } f\} \\ & g(u_i) + h(u_i) \\ = \quad &\{\text{Déf. du coût d'un chemin}\} \\ & g(u_{i-1}) + w(u_{i-1}, u_i) + h(u_i) \\ \geq \quad &\{\text{Déf. de la consistance}\} \\ & g(u_{i-1}) + h(u_{i-1}) \\ = \quad &\{\text{Déf. de } f\} \\ & f(u_{i-1}) \end{aligned} \end{equation*}L'autre implication (viz. monotonicité implique consistance) est triviale.
Aussi, une heuristique consistante est admissible (la réciproque n'est pas vraie). En effet, si \(h\) est consistante, pour toute arête \((u,v)\) nous avons \(h(u) - h(v) \leq w(u,v)\). Soit un chemin quelconque \(p = (v_0 = u,\dots,v_k = t)\), nous avons :
\begin{equation*} \begin{aligned} & w(p) \\ = \quad &\{\text{Déf. du poids d'un chemin}\} \\ & \sum_{i=0}^{k-1} w(v_i, v_{i+1}) \\ \geq \quad &\{\text{Consistance de } h\} \\ & \sum_{i=0}^{k-1} h(v_i) - h(v_{i+1}) \\ = \quad &\{\text{Arithmétique}\} \\ & h(u) - h(t) \\ = \quad &\{t \text{ est la cible}\} \\ & h(u) \end{aligned} \end{equation*}En particulier, dans le cas d'un plus court chemin : \(h(u) \leq \delta(u,t)\).
5.2 L'algorithme A*
L'algorithme A* est un exemple d'amélioration de l'algorithme de Dijkstra grâce à l'utilisation d'une fonction heuristique. A* associe à un nœud \(u\) du graphe la valeur :
\begin{equation*} f(u) = g(u) + h(u) \end{equation*}où \(g(u)\) est le poids optimal actuellement connu pour un chemin menant de \(s\) à \(u\), et \(h(u)\) est une heuristique admissible (i.e., une borne inférieure de la distance séparant \(u\) de la cible \(t\) ).
Nous remarquons que pour un nœud \(u\) gris minimal (au sens de \(f(u)\) ), nous avons pour tout successeur \(v\) de \(u\) :
\begin{equation*} \begin{aligned} & f(v) \\ = \quad &\{\text{Déf. de } f\} \\ & g(v) + h(v) \\ = \quad &\{\text{si on devait mettre à jour le poids de } v\} \\ & g(u) + w(u,v) + h(v) \\ = \quad &\{\text{Arithmétique}\} \\ & g(u) + h(u) + w(u,v) - h(u) + h(v) \\ = \quad &\{\text{Déf. de } f\} \\ & f(u) + w(u,v) - h(u) + h(v) \end{aligned} \end{equation*}Ainsi, l'algorithme A* correspond exactement à l'algorithme de Dijkstra avec la repondération suivante :
\begin{equation*} \hat{w}(u,v) = w(u,v) - h(u) + h(v) \end{equation*}Si l'heuristique \(h\) est monotone alors tous les poids restent positifs et la preuve de correction de Dijkstra s'applique !
De plus, nous allons montrer que, dans le cas d'une heuristique monotone, il n'existe pas d'algorithme \(A\) qui trouve la solution optimale en explorant moins de nœuds que \(A^*\). Soit \(f^* = \delta(s,t)\) le coût de la solution optimale. Nous montrons que tout algorithme optimal (i.e., qui trouvera toujours la solution optimale) doit visiter tous les nœuds \(u\) pour lesquels \(\delta(s,u) < f^*\).
Travaillons par l'absurde en supposant qu'il existe un algorithme \(A\) qui trouve une solution optimale \(p_t\) (i.e., avec \(w(p_t) = f^*\) ) en ne visitant pas un nœud \(u\) pour lequel \(\delta(s,u) < f^*\). Montrons qu'il peut alors exister un autre chemin \(q\) avec \(w(q) < f^*\) qui n'est pas trouvé par A. Soit \(q_u\) le chemin tel que \(w(q_u) = \delta(s,u)\). Mettons qu'il existe une arête \((u,t)\) de poids \(0\) (i.e., \(w(u,t) = 0\) ). Puisque le voisinage de \(u\) n'a pas été exploré par \(A\), ce dernier ne peut pas savoir que l'arête \((u,t)\) existe. Soit le chemin \(q = (q_u,t)\). Nous avons : \(w(q) = w(q_u) + w(u,t) = \delta(s,u) < f^*\).
5.3 Comparer des heuristiques
Plus une heuristique \(h(u)\) est proche de la valeur optimale \(\delta(u,t)\) plus elle est informée.
Plus une heuristique est informée, mieux elle minimise la taille de l'espace exploré, mais en général elle est également plus coûteuse en temps de calcul qu'une heuristique moins informée.
6 Exemple sur le jeu de taquin de taille 8
6.1 Contexte
Prenons l'exemple simple du 8-puzzle dont on rappelle ci-dessous le voisinage :
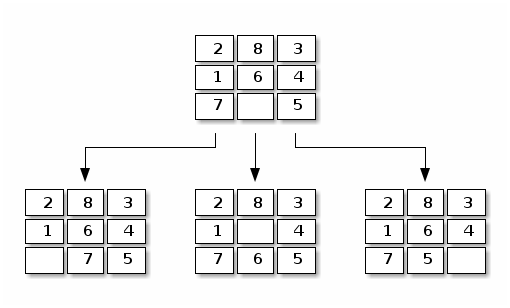
Figure 9: Quatre configurations voisines pour le 8-puzzle
6.2 Heuristiques
Voici quelques exemples d'heuristiques ordonnées par degré d'information :
- nombre de chiffres mal placés
- somme des distances (de manhattan) des chiffres à leurs positions d'origine
- prise en compte des échanges entre cases voisines
- …
6.3 Implémentation
6.3.1 Types (<<taquin-types>>)
Nous commençons par définir le type d'un nœud et d'une fonction heuristique :
// code block taquin-types typedef vector<int> State; // .---. // |2|0| // .---. -> State b = {2,0,1,3} // |1|3| // .---. typedef function<int( const State& pos )> Heuristic;
6.3.2 Taille du côté d'une grille (<<taquin-side>>)
Nous introduisons une fonction accessoire pour calculer la taille du côté d'une grille.
// code block taquin-side int side( const State& b ) { double y = sqrt( b.size() ); int x = y; return x; }
6.3.3 Heuristiques (<<taquin-heuristics>>)
Puis nous définissons trois heuristiques :
// code block taquin-heuristics int breadth( const State& b ) { return 0; } int nbmis( const State& b ) { int d = 0; for( int i = 0 ; i < b.size() ; i++ ) { if( b[i] != 0 ) // not a tile, '0' doesn't count { if( b[i] != i ) d++; } } return d; } int manh( const State& b ) { int d = 0; int s = side(b); for( int i = 0 ; i < b.size() ; i++ ) { if( b[i] != 0 ) // not a tile, '0' doesn't count { d += abs( i / s - b[i] / s ) + abs( i % s - b[i] % s ); } } return d; }
6.3.4 Configuration cible (<<taquin-final_state>>)
La fonction final_state indique si la configuration finale est atteinte :
// code block taquin-final_state bool final_state( const State& b ) { return (nbmis(b) == 0); // we use nbmis for it is quick to compute }
6.3.5 \(A^*\) (<<taquin-astar>>)
Nous adaptons l'algorithme \(A^*\) (i.e. Dijkstra…) à ce contexte :
// code block taquin-astar void astar( const State& initial_state, Heuristic h, list<State> *best_path, int *nbiter ) { <<taquin-astar-init>> while( !grey.empty() ) { State current_state = grey.top().second; (*nbiter)++; if( final_state(current_state) ) { <<taquin-astar-stop>> return; } black.insert(current_state); // current_state becomes black... grey.pop(); // ...it is no more grey <<taquin-astar-neighbors>> for( State neighbor : neighbors ) { <<taquin-astar-update>> } } }
6.3.6 Distance pour les noeuds gris et noirs (<<taquin-astar-dist>>)
Nous utilisons une fonction pour retourner la plus petite distance actuellement connue pour rejoindre un nœud donné. Dans le cas d'un nœud pour lequel aucune estimation de distance n'a pour l'instant été proposée, cette fonction retourne l'infini :
// code block taquin-astar-dist int dist( const map<State,int>& d, const State& state ) { map< State , int >::const_iterator it = d.find(state); if( d.end() == it ) { return numeric_limits<int>::max(); } return it->second; }
6.3.7 Mise à jour de la file de priorité (<<taquin-astar-update>>)
La mise à jour de la file de priorité ne pose pas de difficulté. Nous utilisons
la repondération de l'algorithme \(A^*\) avec l'heuristique h et avec un coût de
base de \(1\) entre deux configurations voisines :
// code block taquin-astar-update if( black.end() != black.find(neighbor) ) // when neighbor n of u is black... { continue; // ...nothing to do } // when it is white or grey... int new_cost = d[current_state] + 1 - h(current_state) + h(neighbor); if( dist(d,neighbor) > new_cost ) // ...we may update the shortest known distance to it { d[neighbor] = new_cost; parent[neighbor] = current_state; grey.push( { d[neighbor] , neighbor } ); }
6.3.8 Rerconstruction du chemin solution (<<taquin-astar-stop>>)
Quand une solution optimale est trouvée, nous reconstruisons le chemin y menant :
// code block taquin-astar-stop best_path->clear(); while( current_state != initial_state ) { best_path->push_front(current_state); current_state = parent[current_state]; } best_path->push_front(initial_state);
6.3.9 Calcul des voisins (<<taquin-astar-neighbors>>)
Pour calculer les voisins neighbors de current_state, nous utilisons quelques petites
astuces algébriques :
// code block taquin-astar-neighnors neighbors.clear(); int pos0 = find( current_state.begin(), current_state.end(), 0 ) - current_state.begin(); if( (pos0 + 1) < current_state.size() && ((pos0 + 1) % s) != 0 ) { State neighbor = current_state; swap( neighbor[pos0] , neighbor[pos0 + 1] ); neighbors.push_back(neighbor); } if( (pos0 - 1) >= 0 && ((pos0 - 1) % s) != (s-1) ) { State neighbor = current_state; swap( neighbor[pos0] , neighbor[pos0 - 1] ); neighbors.push_back(neighbor); } if( (pos0 + s) < current_state.size() ) { State neighbor = current_state; swap( neighbor[pos0] , neighbor[pos0 + s] ); neighbors.push_back(neighbor); } if( (pos0 - s) >= 0 ) { State neighbor = current_state; swap( neighbor[pos0] , neighbor[pos0 - s] ); neighbors.push_back(neighbor); }
6.3.10 Initialisation des structures de données (<<taquin-astar-init>>)
L'initialisation ne pose pas de difficulté, sinon qu'avec la nouvelle pondération de \(A^*\) il faut penser à initialiser le poids de la source avec la valeur de l'heuristique :
// code block taquin-astar-init int s = side(initial_state); map< State , State > parent; parent[initial_state] = initial_state; map< State , int > d; d[initial_state] = h(initial_state); set< State > black; priority_queue< pair< int , State >, vector< pair< int, State > >, greater< pair< int, State > > > grey; grey.push( { d[initial_state], initial_state } ); // initially the source is grey vector<State> neighbors; (*nbiter) = 0;
6.3.11 Afficher une grille (<<taquin-print>>)
Nous introduisons une fonction accessoire pour afficher une grille :
// code block taquin-print void print( const State& state ) { int s = side(state); for( int i = 0 ; i < state.size() ; i++ ) { if( i % s == 0 ) cout << endl; cout << setw(2) << setfill('0') << state[i] << " , "; } cout << endl; }
6.3.12 Librairies utilisées (<<taquin-include>>)
// code block taquin-include #include <iostream> #include <vector> #include <set> #include <queue> #include <map> #include <utility> #include <list> #include <functional> #include <cmath> #include <algorithm> #include <utility> #include <iomanip> #include <limits> using namespace std;
6.3.13 Programme principal (taquin.cpp)
Nous testons le programme sur une petite grille de côté \(8\).
// code block taquin.cpp <<taquin-include>> <<taquin-types>> <<taquin-side>> <<taquin-heuristics>> <<taquin-final_state>> <<taquin-print>> <<taquin-astar-dist>> <<taquin-astar>> int main() { State b = {4,8,3,2,0,7,6,5,1}; list<State> best_path; int nbiter = 0; astar(b, breadth, &best_path, &nbiter); cout << "Heuristic breadth:" << endl; cout << "nb moves: " << best_path.size()-1 << endl; cout << "nb nodes explored: " << nbiter << endl; /* for( list<State>::iterator it = best_path.begin() ; it != best_path.end() ; it++ ) { print( (*it) ); } */ best_path.clear(); astar(b, nbmis, &best_path, &nbiter); cout << "Heuristic nbmis:" << endl; cout << "nb moves: " << best_path.size()-1 << endl; cout << "nb nodes explored: " << nbiter << endl; /* for( list<State>::iterator it = best_path.begin() ; it != best_path.end() ; it++ ) { print( (*it) ); } */ best_path.clear(); astar(b, manh, &best_path, &nbiter); cout << "Heuristic manh:" << endl; cout << "nb moves: " << best_path.size()-1 << endl; cout << "nb nodes explored: " << nbiter << endl; /* for( list<State>::iterator it = best_path.begin() ; it != best_path.end() ; it++ ) { print( (*it) ); } */ return 0; }
6.4 Résultats
- heuristique
breadth- 20 coups
- 44696 nœuds explorés
- heuristique
nbmis- 20 coups
- 2877 nœuds explorés
- heuristique
manh- 20 coups
- 189 nœuds explorés
7 Exemple sur le jeu de taquin de taille 15
// code block: taquin15.cpp <<taquin-include>> <<taquin-types>> <<taquin-side>> <<taquin-heuristics>> <<taquin-final_state>> <<taquin-print>> <<taquin-astar-dist>> <<taquin-astar>> int main() { //State b = {4,8,3,2,0,7,6,5,1}; // C0 small problem easily solved by A* State b = {7,11,8,3,14,0,6,15,1,4,13,9,5,12,2,10}; // C1 easy configuration that can also be solved by A* //State b = {14,10,9,4,13,6,5,8,2,12,7,0,1,3,11,15}; // C2 more difficult configuration that will not be solved by A* (with 6 GB of RAM) list<State> best_path; int nbiter = 0; astar(b, manh, &best_path, &nbiter); cout << "Heuristic manh:" << endl; cout << "nb moves: " << best_path.size()-1 << endl; cout << "nb nodes explored: " << nbiter << endl; return 0; }
Sur cette instance, nous n'arrivons pas à trouver une solution… L'algorithme A* en tant que variante de la recherche en largeur est gourmand en mémoire (toutes les configurations de coût inférieur à la solution optimale sont mémorisées).
8 Approfondissement itéré (iterative deepening)
Il s'agit de faire un parcours en profondeur jusqu'à une profondeur maximale \(n\). Si aucune solution n'est trouvée, une nouvelle recherche est lancée jusqu'à une profondeur maximale \(n+1\). Etc.

Figure 10: Recherche en profondeur avec approfondissement itéré
Soit \(N_b(d)\) le nombre de nœuds d'un espace d'états structuré en arbre enraciné de profondeur \(d\) et de facteur de branchement \(b\) (i.e., chaque nœud qui n'est pas une feuille possède \(b\) fils). Nous avons :
\begin{equation*} N_b(d) = \sum_{i=0}^{d} b^i = \frac{b^{d+1} - 1}{b - 1} \end{equation*}Ainsi :
\begin{equation*} \begin{aligned} & \sum_{d=1}^{d_{max}-1} N_b(d) \\ = \quad & \sum_{d=1}^{d_{max}-1} \frac{b^{d+1}-1}{b-1} \\ = \quad & \frac{1}{b-1} \left(\left( \sum_{d=1}^{d_{max}-1} b^{d+1} \right) - d_{max} + 1 \right) \\ = \quad & \frac{1}{b-1} \left(\left( \sum_{d=2}^{d_{max}} b^d \right) - d_{max} + 1 \right) \\ = \quad & \frac{1}{b-1} \left( \frac{b^{d_{max}+1} - 1}{b - 1} - 1 - b - d_{max} + 1 \right) \\ = \quad & \frac{1}{b-1} N_b(d_{max}) - \dots \end{aligned} \end{equation*}Donc, à partir d'un facteur de branchement \(b > 2\), il y a moins de nœuds dans la somme de tous les arbres excepté le dernier que de nœuds dans le dernier arbre. Ce raisonnement justifie l'utilisation de l'approfondissement itéré qui peut permettre une économie en mémoire sans que les visites multiples d'un même noeud aient un impact sur le nombre totale d'opérations lors de l'exécution de l'algorithme.
9 Approfondissement itéré pour l'algorithme A* (IDA*)
9.1 Algorithme

Figure 11: Algorithme A* avec approfondissement itéré
9.2 Exercice
Vous devez implémenter la procédure SEARCH de l'algorithme \(IDA^*\) en partant
du code source suivant : ida_tp.cpp. Dans la fonction main, vous trouverez
décrites trois configurations initiales (C0, C1 et C2) que vous utiliserez
pour vos expérimentations. Par ailleurs, vous utiliserez également le code source
déjà développé en cours pour l'algorithme A* : taquin15.cpp. Vous devez
répondre aux questions suivantes sur Moodle :
- Si
A*ne parvient pas à résoudre le taquin à partir deC2, est-ce d'abord par manque…- …de temps ?
- ou de mémoire ?
- La quantité de mémoire utilisée par
A*est-elle linéairement proportionnelle…- …à la taille d'un chemin solution ?
- …au nombre de solutions partielles de coût inférieur à la solution optimale ?
- …à la taille de l'espace d'états ?
- Combien de recherches en profondeur effectue
IDA*pour résoudre le taquin à partir deC0? - Combien de recherches en profondeur effectue
IDA*pour résoudre le taquin à partir deC1? - La quantité de mémoire utilisée par
IDA*est-elle linéairement proportionnelle…- …à la taille d'un chemin solution ?
- …au nombre de solutions partielles de coût inférieur à la solution optimale ?
- …à la taille de l'espace d'états ?
- Quelle est la longueur (en nombre d'actions) de la solution optimale pour
C2? - En comparaison avec une version de l'algorithme pour laquelle les voisins d'un
état sont explorés dans un ordre quelconque, la version meilleur d'abord
(explorant les voisins d'un état par ordre croissant de la valeur heuristique
h) pourra explorer…
- …plus d'états ?
- …moins d'états ?
- …au moins autant d'états que ceux vus lors des premiers \(n-1\) parcours en profondeur (la solution étant trouvée au cours du \(n\)-ème parcours) ?
Plusieurs réponses sont possibles.
10 Recherche locale itérative et recuit simulé
10.1 Hill-Climbing
L'approche de recherche locale itérative la plus naïve pour la résolution d'un problème combinatoire est le "hill-climbing" (similaire à la ``descente de gradient'' dans le cas de fonctions continues dérivables). Il s'agit de générer une solution initiale puis, tant que possible, se déplacer vers une solution voisine meilleure.

Figure 12: Algorithme Hill-Climbing pour la recherche locale
Le problème principal de cette approche est qu'un optimum local peut être très éloigné de l'optimum global.
10.2 Recuit simulé
Le recuit simulé ("simulated annealing") est un algorithme itératif qui apporte une solution au problème de l'attraction par les optimums locaux. Une solution voisine meilleure que la solution actuelle sera toujours acceptée. Une solution voisine moins bonne que la solution actuelle sera parfois acceptée selon la probabilité :
\begin{equation*} e^{\frac{f(u)-f(v)}{kT}} \end{equation*}En thermodynamique, la probabilité de trouver un système dans un état d'énergie \(E\) à une température \(T\) est proportionnelle à \(e^{-\frac{E}{kT}}\) où \(k\) est la constante de Boltzmann (\(1.3896 \times 10^{-23}\) joule/kelvin). Le facteur de Boltzmann est le rapport entre deux états d'énergies \(E1\) et \(E2\): \(e^{-\frac{\Delta E}{kT}}\).
Par exemple, une molécule de gaz dans l'atmosphère terrestre a son plus bas niveau d'énergie au niveau de la mer. Son énergie augmente avec l'altitude. La probabilité de trouver la molécule 10 mètres au dessus du niveau de la mer est presque identique à celle de la trouver au niveau de la mer car \(\Delta E\) est très petit par rapport à \(kT\). Le ratio des probabilités de ces deux niveaux d'énergie est proche de 1. Mais quand l'altitude augmente, la différence des probabilités des niveaux d'énergie augmente. La probabilité de trouver la molécule à une haute altitude décroit exponentiellement avec l'augmentation linéaire de l'altitude. Par contre, si la température augmente, la probabilité de trouver une molécule à une haute altitude augmente également.
Ainsi, le recuit simulé débute avec une température élevée qui permet d'explorer de nombreuses solutions en s'échappant des minimums locaux. Un refroidissement progressif permet d'approcher une bonne solution de faible énergie.
Ci-dessous des graphes de cette distribution pour différentes valeurs de \(T\) (dessinés avec le langage J) : \(2\) en bleu, \(3,3\) en rouge et \(10\) en vert.
load 'plot numeric' plot (; ^@*&0.3 , ^@*&0.5 ,: ^@*&0.1) steps _2 0 20
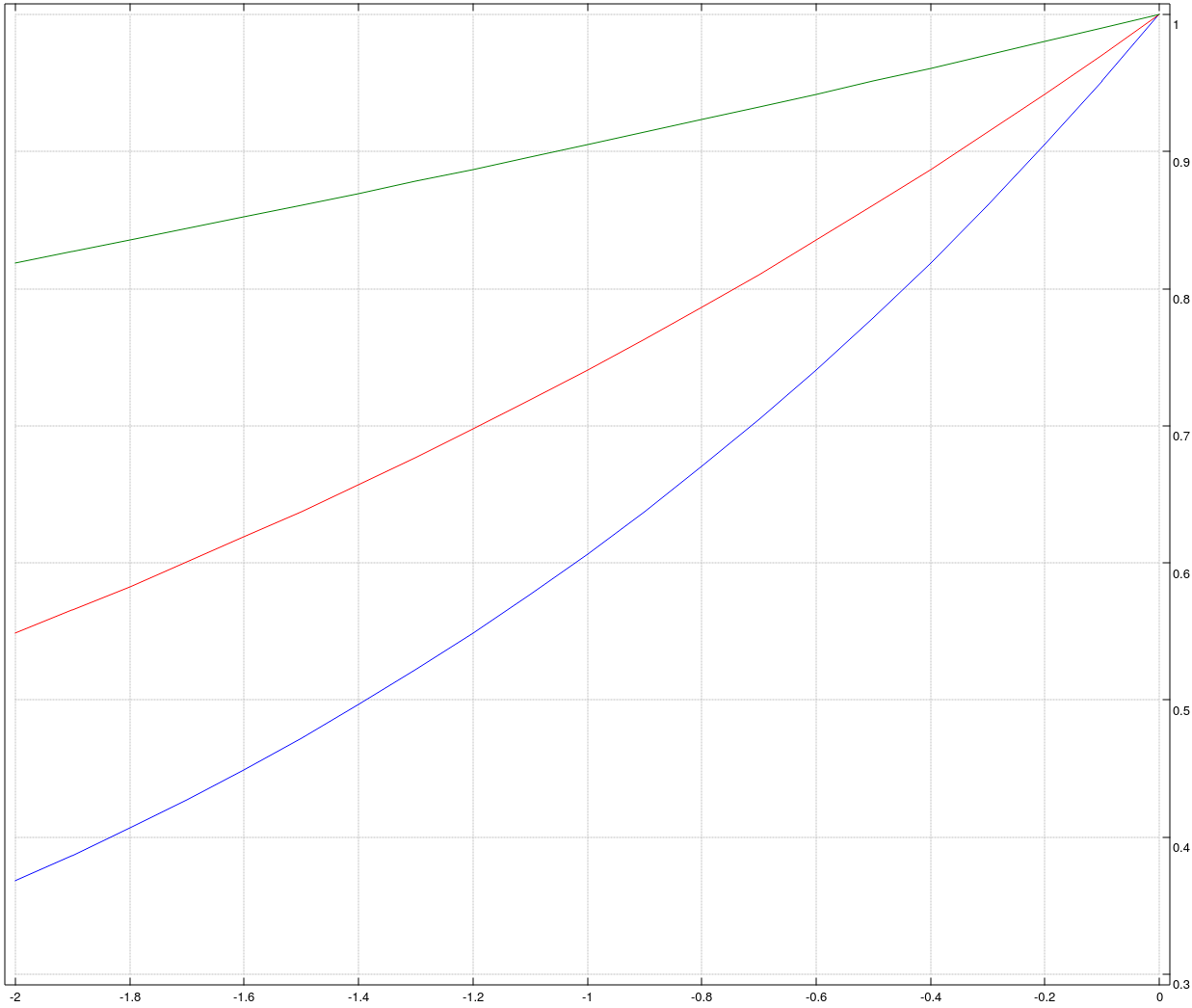

Figure 14: Recuit simulé
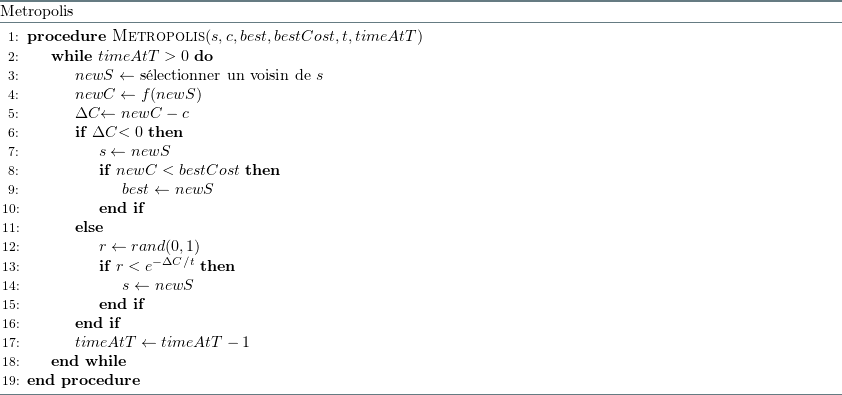
Figure 15: Metropolis
10.3 Générateur de nombre aléatoire
Nous commençons par introduire un générateur de nombres aléatoires classique qui sera utilisé pour l'implémentation de l'algorithme itératif du recuit simulé. Nous avons besoin d'un générateur qui respecte une distribution uniforme. Il s'agit par exemple de générer aléatoirement un nombre à virgule flottante sur l'intervalle \([0.0 .. 1.0]\) et chaque nombre doit être équiprobable.
Commençons par quelques remarques générales :
- Nous aurons besoin de l'implémentation d'opérations arithmétiques sur des valeurs codées avec 64 bits et non signées.
- Une notion clé sera la période du générateur qui ne devrait pas être inférieure à \(\text{~} 2^{64}\).
- Il ne faudra pas utiliser les implémentations par défaut des langages C,
C++, Matlab, etc. (e.g.,
rand,srand, etc.) car leur implémentation n'étant pas standardisée, elles ne sont pas toujours d'une qualité suffisante (nous allons comprendre pourquoi…).
10.3.1 Approche par congruence linéaire
Les premiers générateurs conçus dans les années 1950 sont fondés sur un principe de congruence linéaire (LCG : linear congruential generator). Il s'agit d'utiliser une équation de récurrence linéaire :
\begin{equation*} I_{j+1} = aI_j + c \; (mod \; m) \end{equation*}Sont particulièrement intéressants les triplets \((a,c,m)\) tels que la période de la récurrence atteigne \(m\).
Malheureusement, il y a des corrélations entre sous-séquences de la récurrence. Par exemple, si des séquences de taille \(k\) sont utilisées pour générer des points dans un espace à \(k\) dimensions, ces points vont se répartir sur des (k-1)-hyperplans parallèles entre eux (au plus \(m^{1/k}\) plans).
Ainsi, la méthode du test spectral a été introduite pour mesurer la qualité d'un générateur LCG (pour aller plus loin que ce rapide survol, voir la section 3.3.4 de "The Art of Computer Programming" de Donald Knuth).
Soit \(< I_n >\) la séquence de période \(m\) associée au générateur (i.e., on suppose que le triplet \((a,c,m)\) a été choisi de telle sorte que la période du générateur soit effectivement \(m\) ). On considère l'ensemble des \(m\) points :
\begin{equation*} \{ \frac{1}{m} (I_n,\dots,I_{n+t-1}) \; | \; 0 \leq n < m \} \end{equation*}d'un espace à \(t\) dimensions. En posant : \(s(x) = ax + c \; (mod \; m)\), cet ensemble s'écrit :
\begin{equation*} \{ \frac{1}{m} (x, s(x), \dots,s^{t-1}(x)) \; | \; 0 \leq x < m \} \end{equation*}Le graphe de cet ensemble de points montre des régularités : les \(t\)-uplets de nombres aléatoires vivent sur des hyperplans parallèles de dimensions \(t-1\).
Par exemple, en dimension 2 on notera \(1/\nu_2\) la distance maximale entre deux lignes parallèles ; le maximum étant pris sur l'ensemble des familles de lignes parallèles qui couvrent chacune les points \((x/m, s(x)/m)\).
\(\nu_t\) est appelée la précision du générateur aléatoire.
Pour fixer les idées, il semble assez juste de dire qu'une suite de \(t\) nombres générés aléatoirement correspond à une suite de \(t\) nombre "vraiment" aléatoires mais tronqués aux plus proches multiples de \(1/\nu_t\) (ou, de manière équivalente, dont la représentation est tronquée à \(log(\nu_t)\) bits). Il faut bien noter que la précision \(\nu_t\) diminue avec l'augmentation de \(t\) (c'est assez intuitif car la période \(m\), et donc le nombre de points, reste constante).
Pour se rendre compte du problème et voir des graphes de tests spectraux pour des générateurs traditionnels, se référer au travail de Entacher : "A collection of selected pseudorandom number generators with linear structures". En fait, beaucoup de générateurs très utilisés ne sont pas satisfaisants (voir par exemple le cas de Matlab).
10.3.2 Approche par équivalence booléenne
Nous introduisons une autre technique fondée sur l'équivalence booléenne (en fait sa négation notée \(\not\equiv\) ou \(\oplus\), i.e. le XOR). Puis nous proposerons une combinaison de ces deux techniques afin de fournir un générateur de nombres aléatoires de qualité.
Une technique très simple consiste à faire trois shift et trois xor pour
calculer le prochain nombre aléatoire :
Afin de comprendre le principe de cette approche, considérons \(x\) comme un vecteur de \(\mathbb{Z}/2\mathbb{Z}^{64}\) (i.e., un vecteur de dimension 64 dont chaque composante est une valeur booléenne). Nous nous plaçons ainsi dans un espace vectoriel avec pour "addition" \(\oplus\) et pour "multiplication" \(\wedge\).
Prenons un exemple simple dans un espace à trois dimensions :
\begin{equation*} (011)_2 \oplus (\; (011)_2 >> (001)_2 \;) = (011)_2 \oplus (001)_2 = (010)_2 \end{equation*}Nous proposons une notation matricielle équivalente :
\begin{equation*} \begin{pmatrix} 1 & 0 & 0 \\ 1 & 1 & 0 \\ 0 & 1 & 1 \end{pmatrix} \bullet \begin{pmatrix} 0 \\ 1 \\ 1 \end{pmatrix} = \begin{pmatrix} 0 \\ 1 \\ 0 \end{pmatrix} \end{equation*}Ainsi, \(x \oplus (x >> a_1)\) équivaut au produit matriciel \(S_{a_1} \bullet x\). Avec, sur notre petit exemple à 3 dimensions, la matrice :
\begin{equation*} S_1 = \begin{pmatrix} 1 & 0 & 0 \\ 1 & 1 & 0 \\ 0 & 1 & 1 \end{pmatrix} \end{equation*}Donc, le calcul du prochain nombre aléatoire correspond à la transformation linéaire : \(T = S_{a_3} S_{a_2} S_{a_1}\).
Il faut trouver des triplets \((a_1, a_2, a_3)\) tels que la période de la séquence aléatoire générée soit \(M = 2^{64} - 1\) (\(2^{64}\) est impossible car le \(0\) est absorbant). Il faut et il suffit que \(T^M = 1\) et \(T^N \neq 1\) pour tout \(N \in \{M/6700417 \; , \; M/65537 \; , \; M/641 \; , \; M/257 \; , \; M/17 \; , \; M/5 \; , \; M/3\}\) (i.e., \(M\) divisé par ses facteurs premiers).
10.3.3 Un générateur simple et fiable
Finalement, nous proposons un générateur qui a de bonnes propriétés et qui est
simplement la combinaison des deux stratégies introduites plus haut (i.e.,
congruence linéaire et utilisation du XOR).
Nous utilisons un raccourci (Ullong) pour le type entier 64 bits, ce type
fonctionnera avec la plupart des compilateurs (dont GNU g++) mais peut-être pas
tous car ce type n'est pas dans le standard C++.
Le code du générateur aléatoire vient de l'ouvrage "Numerical Recipes, the Art of Scientific Computing" :
struct Ran { Ullong v; Ran(Ullong j) : v(4101842887655102017LL) { v ^= j; v = int64(); } inline Ullong int64() { v ^= v >> 21; v ^= v << 35; v ^= v >> 4; return v * 2685821657736338717LL; } inline double doub() { return 5.42101086242752217E-20 * int64(); } inline uint int32() { return (uint)int64(); } };